We are using the following config:
- 300C unit
- 2 WAN connections
- Spillover load balancing
Fortinet suggests here to do the following:
- Configure static routes
- Configure spillover thresholds
- Configure interface status detection
Static routes
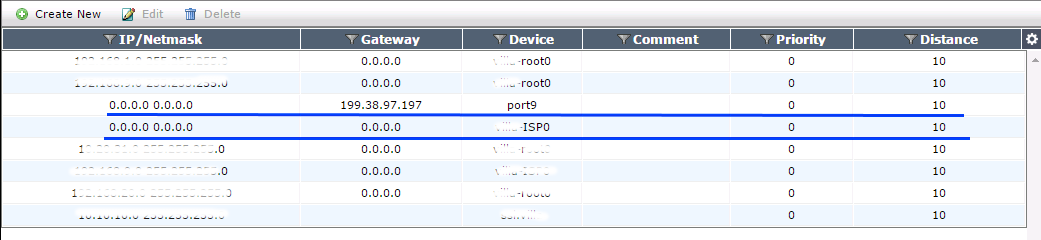
- Notice that the distance is set to the same value: in this config, the unit is supposed to select the shortest distance automatically and use it threshold is reached. Well it does not work as we will see in the images bellow.
- In the initial setup under FortiOS 5.0, we had ISP0 distance set to 11 so that, according to the latest documentation, all connections go to port9 until threshold is reached. It did work before we have migrated to 5.2 but is clearly not working now.
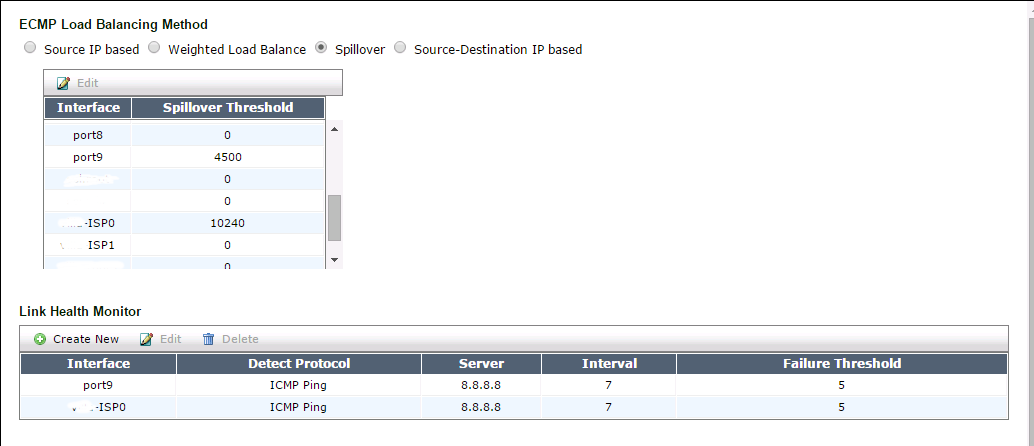
The behavior in FortiOS 5.2
 |
| Normal behavior with 30+ users for the past hour |
Notice how the second WAN connection is not getting used at all? Considering that there are multiple users and the link gets saturated well above the threshold of 4500kbits set in the ECMP balancing (it gets up to 5.2Mbit=5320kbits), it is a weird behavior that should not occur in a normal usage scenario.
 |
| Simulating WAN connection down |
However, it looks like fail-over is working???
Will it then load balance after we bring back the main connection?

Well, it does go back to main connection.and completely drops the second one. Despite the fact that during downtime of WAN1 the routes in cash were using WAN2, the system almost immediately comes back to the same old behavior we have noticed earlier: all connections are reset to WAN 1.
Conclusion: spillover does not work. We can at best hope for fail-over.
We can even go farther and diagnose connection behavior:
Let us change the spill-over threshold to 1 for port9. In CLI, we will go to a VLAN that has the above setup (if any) and type the following command :
diagnose netlink dstmac list
The output is the following:
dev=port9 mac=00:00:00:00:00:00 rx_tcp_mss=0 tx_tcp_mss=0 overspill-threshold=128 bytes=308 over_bps=1 sampler_rate=0
By comparing overspill-threshold (in bytes) and bytes (actual usage in bytes) value we can see that the connection has reached over its new threshold. Moreover, over_bps=1 indicates that the unit has detected the limit and is supposed to forward new connections to the second port. By going to VDOM-->Log and repport-->Traffic Log --> Forward traffic we can examine the behavior and we notice that the spill-over actually works! yes it does! But what has happened previously?
Well, if we put the values back as they were and we generate lots of various traffic from various sources (plus there are some unsuspecting users using the network right now), we get the following:
dev=port9 mac=00:00:00:00:00:00 rx_tcp_mss=0 tx_tcp_mss=0 overspill-threshold=576000 bytes=132 over_bps=0 sampler_rate=0
dev=port9 mac=00:00:00:00:00:00 rx_tcp_mss=0 tx_tcp_mss=0 overspill-threshold=576000 bytes=54 over_bps=0 sampler_rate=0
dev=port9 mac=00:00:00:00:00:00 rx_tcp_mss=0 tx_tcp_mss=0 overspill-threshold=576000 bytes=162 over_bps=0 sampler_rate=0
dev=port9 mac=00:00:00:00:00:00 rx_tcp_mss=0 tx_tcp_mss=0 overspill-threshold=576000 bytes=66 over_bps=0 sampler_rate=0
While the connection looks like this:

Despite the fact that the WAN1-port9 interface is saturated well above spill-over limit, a short inspection of logs shows that no spill-over occurs and all connections that have been previously forced to a second WAN are now back to WAN1. All this is due to the fact that something is wrong with the setup and/or detection of the traffic: it simply cannot vary between 54 and 162 bytes when we see 5.2Mbit (more than 681 000 bytes) of traffic. Clearly 15 minutes above are not enough to be able to see any effect of load-balancing, especially under lab conditions, but the unit still should indicated that a limit spill-over has been reached (over_bps=1 should be set for port9).
Unfortunately, I do not have time or energy to investigate this farther. Tomorrow, I and my companion will redo the entire setup and use the new load balancing method. The idea comes from the official Fortinet YouTube channel. Note however that the settings are actually elsewhere in our v5.2.1,build618 (GA) FortiOS:
VDOM_NAME-->Network--> WAN Link Load Balancing Interface
or if you do not have VDOMs
System-->Network--> WAN Link Load Balancing Interface
I do not want to bother fixing the above not because I like so much re-configuring everything but because the new setup has a promise to simplify IPv4 tables and reduce by half the amount of policies we have currently: WAN1 and WAN2 have the same policies. Hopefully it will work as expected.
UPDATE 21/10/2014: So we have tried for almost 7 hours to make it work and we failed. We had to revert back to the above described method because the system was unstable: pings and connections were dropping for no known (to us) reason. I have created a ticket with Fortinet and will keep you posted.
UPDATE 23/12/2014: The answer was easy... but the issue of proper loadbalancing was not solved. See my post: [3 of many] Migrating to Fortinet 5.2 - ECMP Load Balancing - Answers
UPDATE 21/10/2014: So we have tried for almost 7 hours to make it work and we failed. We had to revert back to the above described method because the system was unstable: pings and connections were dropping for no known (to us) reason. I have created a ticket with Fortinet and will keep you posted.
UPDATE 23/12/2014: The answer was easy... but the issue of proper loadbalancing was not solved. See my post: [3 of many] Migrating to Fortinet 5.2 - ECMP Load Balancing - Answers

